
Why Your Exact-Match, High-Quality Blog Not Rank Even in Top 100
You searched your keyword expecting at least something—maybe page 3, maybe page 5. Or worse, if page 10…
Instead, you go all the way to page 8, 9, 10… and you see pages that don’t even properly answer the query. Old articles, loosely related blogs, and random category pages are ranking. And your post? Not even in the top 100.
It would happen sometimes to you, but not often.
Here’s the direct answer:
Your content is not ranking because Google does not trust your site enough yet—not because your content is bad.
And those unrelated pages you’re seeing? They’re not better. They’re just safer bets for Google.
Once you understand that, everything else starts making sense.
The Real Truth (That Most SEO Advice Avoids)
Most advice keeps telling you to: improve content, add more depth, optimise keywords, and build backlinks.
But here’s the thing—none of that matters if Google hasn’t decided you’re a reliable source yet.
Google is not primarily a content judge. It’s a risk manager.
Before it asks, “is this the best answer?”, It asks:
“Can I safely send users to this site?”
If the answer is uncertain, your page doesn’t even enter the competition. It just sits outside while Google fills results with sites it already knows.
Think about it in real-life terms. If you’re recommending a doctor to a friend, you’ll pick someone you’ve heard of—even if another doctor might technically be better but completely unknown to you. Google works the same way, just at a massive scale.
The Actual Reasons Behind This
Let’s break it down properly, because this is where most people get confused.
1. Google prefers trusted over perfect
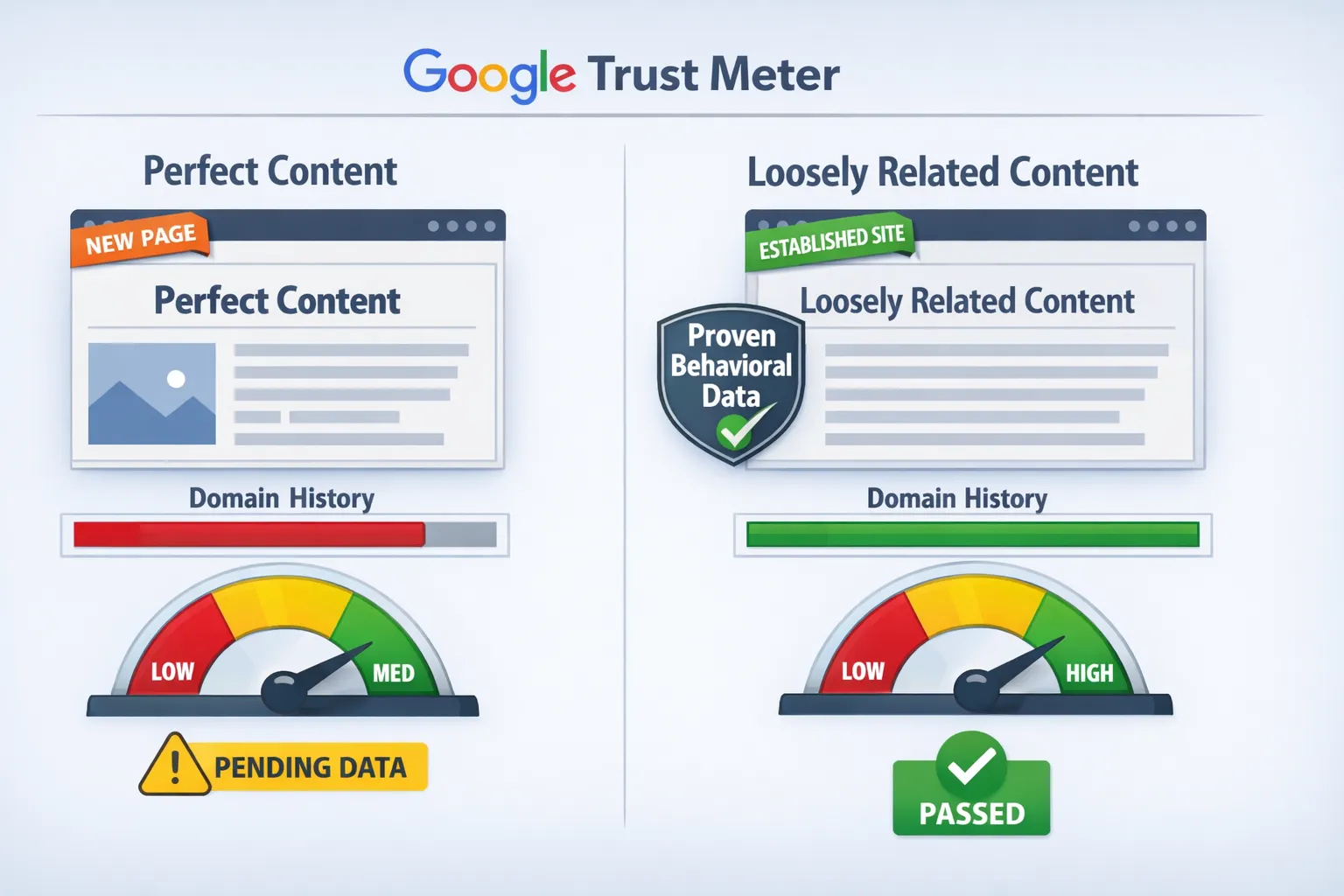
If your page is a perfect match but from a new site, and another page is only loosely related but from an established domain, Google will almost always pick the established one. It is the Trusted Trash Rule.
Why? Because it has a history of consistent signals over time.
It knows how users behave on that site. They know people don’t immediately bounce. That reduces risk.
You, on the other hand, are unknown. You lack history, behavioural data, and a proven track record.
2. New domains go through a “wait and watch” phase
This is not some mythical sandbox—it’s just how the system works.
Google has seen thousands of sites appear, publish aggressively, and disappear or turn spammy within months. So when your site shows up, even with excellent content, the system holds back.
It’s basically saying, ‘Let’s see if this site is still consistent after a few months.’
That’s why new pages don’t rank instantly, even if they’re excellent. They’re discovered, indexed, but not fully trusted yet.
3. You don’t have topical authority yet (Halo Effect)
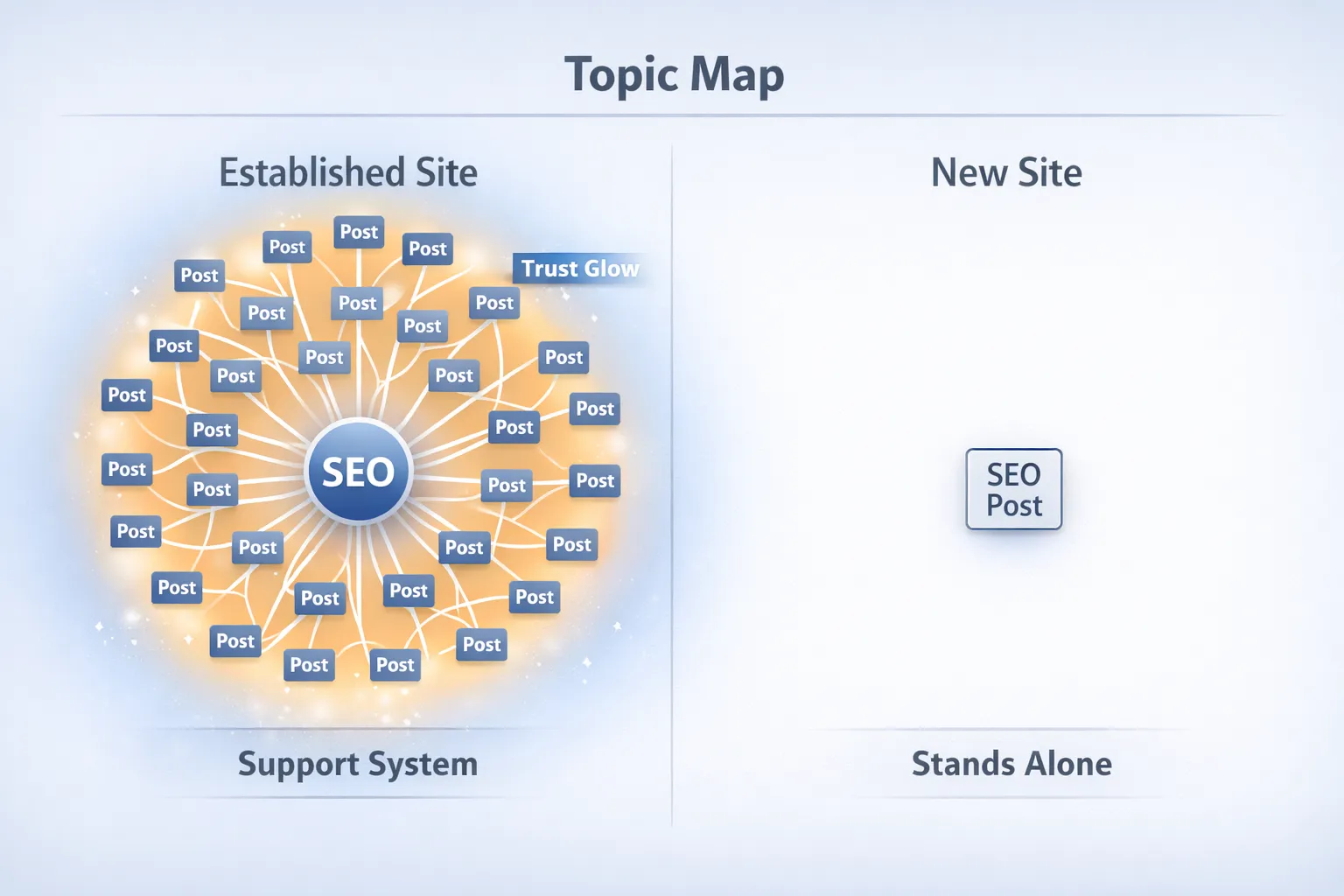
Big sites don’t rank because each page is amazing. They rank because Google understands their entire site.
If a site has hundreds of posts about SEO, Google maps it as an SEO authority. Thereafter, even slightly relevant posts can rank because the domain itself carries weight of topical authority.
Every post you publish is judged on its own, because you don’t yet have trust signals working across multiple pages.
4. Google expands the query when it runs out of trusted results
When Google can’t find enough trusted pages that exactly match a query, it doesn’t stop—it expands.
It starts pulling results from broader, related topics just to fill the SERP.
That’s why you see weird, unrelated pages on later pages. They’re not answering your query directly—they’re part of an expanded interpretation.
Your post might be the most accurate answer, but if it’s not trusted, it gets skipped.
5. The “Entity Connection” (Knowledge Graph Logic)
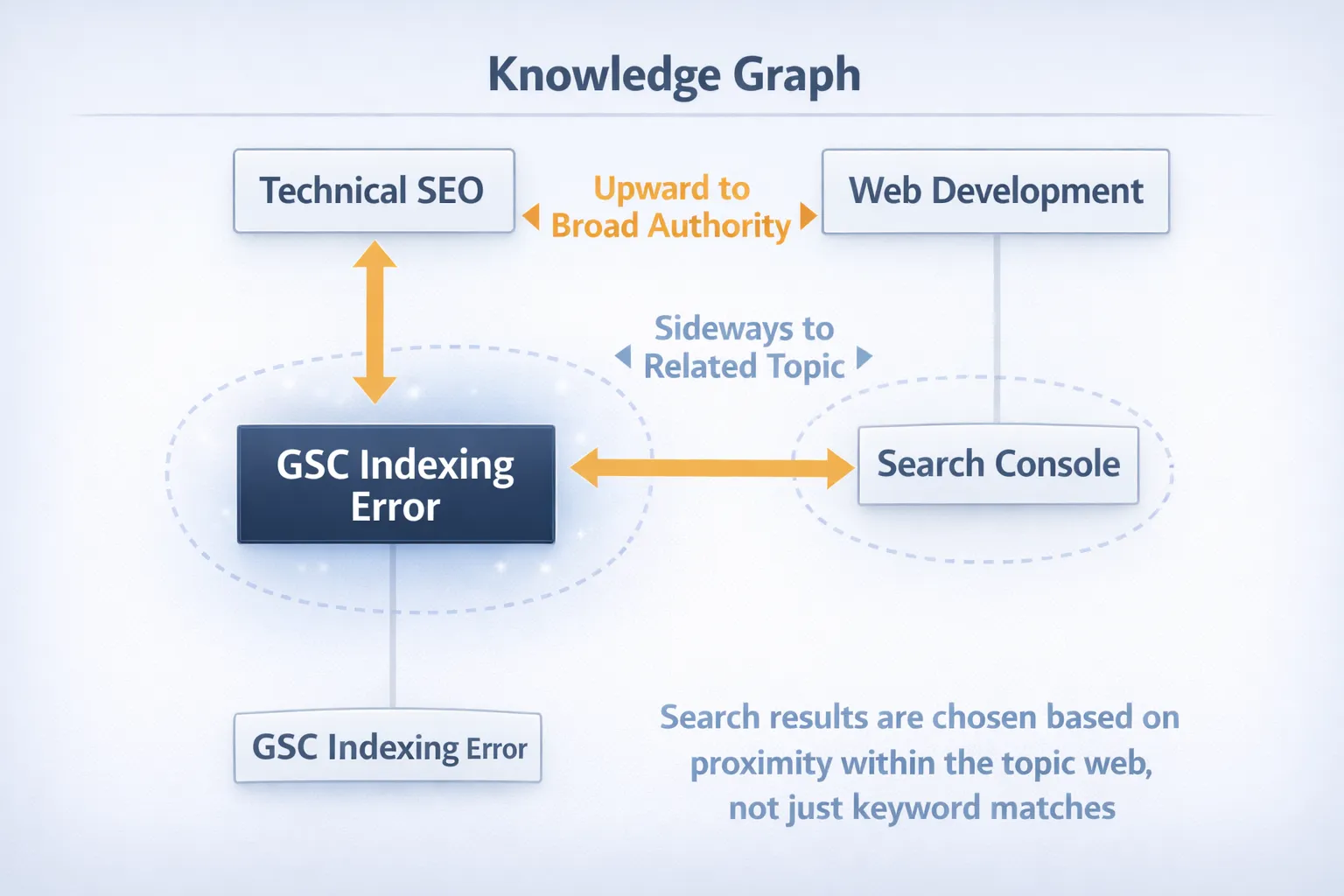
Sometimes results look completely off—like you search a very specific GSC issue and get pages about broader tech or AI topics.
This isn’t random.
Google doesn’t work on keywords alone. It works on entities and their relationships. Your query sits inside a larger topic map. So a specific issue (like a GSC error) is part of a bigger entity like “SEO”, which is further connected to digital marketing, tools, automation, and even AI.
Here’s what matters:
If Google doesn’t trust your page at that specific level, it shifts:
- Upward → to trusted SEO authority sites
- Sideways → to related tech topics
This is semantic backfilling. Google stays on the topic, but not at your exact level.
Your content may be the right answer—but it’s not yet inside Google’s trusted entity network.
6. You have no behavioral data yet
Google relies on user interaction signals:
- Do people click?
- Do they stay?
- Do they come back?
Your page has none of this data yet.
Meanwhile, older pages—even irrelevant ones—have years of user interaction. Even if users don’t find exactly what they want, they often don’t bounce immediately.
To Google, that still looks like a “safe” result.
7. Behavioral “Distraction” vs. “Satisfaction”
This is a subtle reason why irrelevant pages keep ranking.
When users click a big site, they often don’t leave quickly—even if the page isn’t the exact answer. They browse, click other links, and stay on the site.
To Google, that looks like this: user clicked → stayed → didn’t return → satisfied
But in reality, it’s often just distraction, not satisfaction.
Big sites naturally have this behaviour because they have lots of content and internal links. So even weak or irrelevant pages keep sending “positive” signals.
Your page might be more accurate—but without clicks and engagement, Google has nothing to measure yet.
8. E-E-A-T (Why your content isn’t trusted yet)
Your content can be outstanding, but if Google can’t clearly see who is behind it, it holds back.
It’s simply about:
- Who wrote this
- Why they’re credible
- Whether they have real experience
If that’s unclear, your site feels unverified. Bigger sites already have this trust layer, so they get preference—even with average content.
9. YMYL (Why some topics are harder)
For topics like health, finance, or legal, Google is much stricter.
It doesn’t just want good content—it wants the following:
- Proven expertise
- Strong authority
- Clear trust signals
New sites rarely rank here fast. Google prefers a trusted source—even if slightly off—over an unknown one.
10. “Better” Content Is Not Enough Anymore (Information Gain)
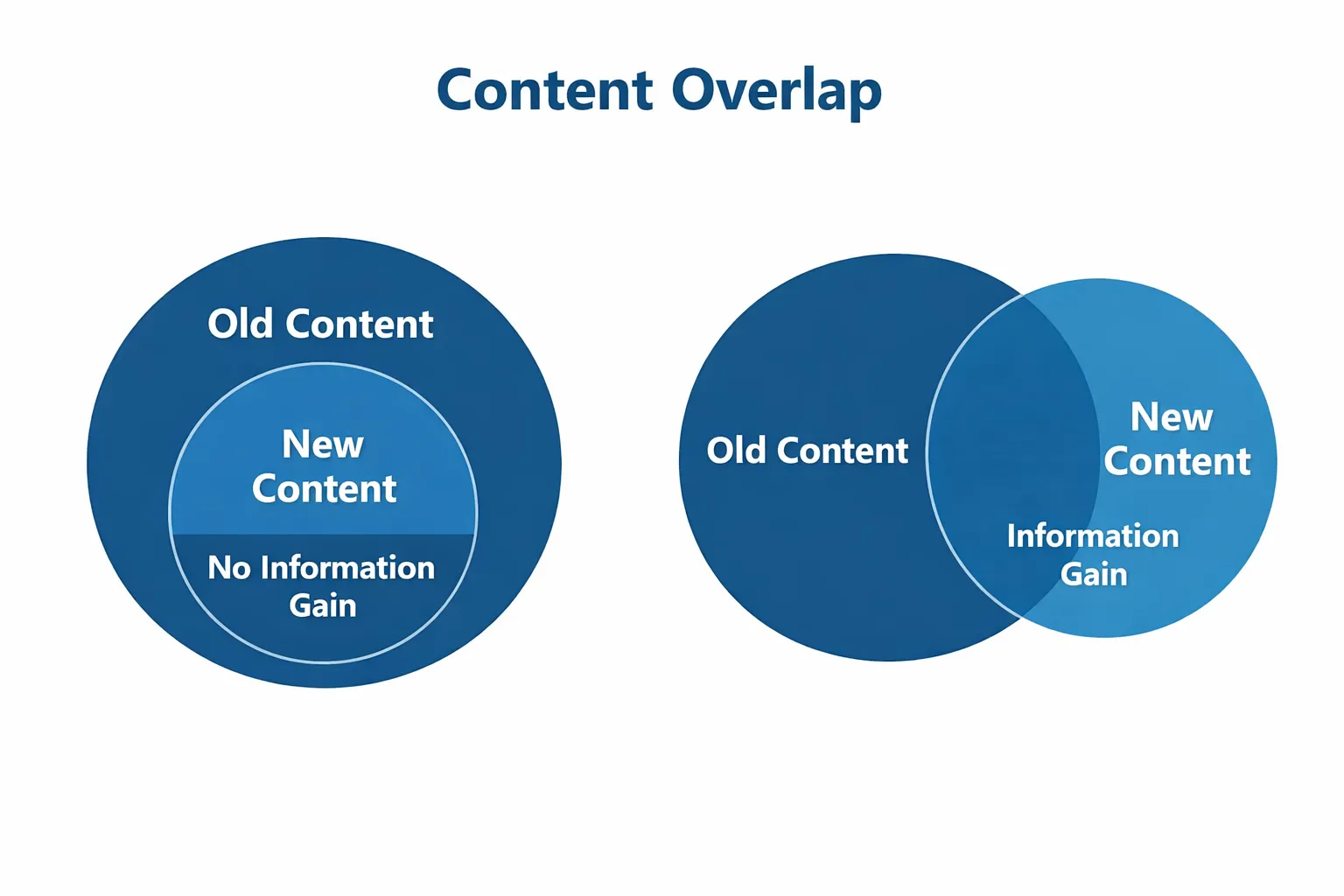
If your article says the same thing as existing results—just written better or clearer—it doesn’t give Google a reason to rank you.
From its perspective, the answer already exists.
Google is effectively asking: Does this page add something new?
That could be:
- A new angle
- New data
- A clearer explanation that changes understanding
If not, there is no information gain. And without that, there’s no reason to replace a trusted result with an untrusted one.
Practical “Trust Audit” — Run This Before Your Next Post
Instead of blindly rewriting, grab a sheet and answer: “Why should Google trust me on this topic?”
- Step 1: Check if you’ve published at least 5–7 articles on the same pillar topic. No? Then your topical authority is low.
- Step 2: See if you have an author bio with real credentials or past work. If missing, Google sees “unverified.”
- Step 3: Search for your exact post title in incognito mode. If it’s past page 5, it’s a trust gap, not a content gap.
- Step 4: Action: Add 3–5 internal links from already indexed pages to the new one. That accelerates “observed” phase.
Do this every time, and you shift from “unknown” to “tested” faster. Google notices consistency more than perfection.
11. New pages take time (this part people ignore)
Even after indexing, pages don’t instantly get ranked properly.
There’s a delay between:
- Being indexed
- Being evaluated
- Being trusted
During this time, your page might sit far outside visible results while Google collects signals.
This is normal, especially for new blogs.
12. Technical distortions you don’t see (silent factors)
There are also a few hidden mechanics that can work against you:
- Title rewriting: Google may change your title to fit broader intent, pushing your page into more competitive spaces
- Document weight: Longer pages often get more initial attention because they contain more signals (entities, links, structure), even if they’re less precise
- SERP personalisation: What you see isn’t always what everyone else sees—results can vary based on history, location, and behaviour.
These don’t override trust—but they can distort how your page is positioned and evaluated.
The conclusion is that your content is a CV. Your trust signals are the references. Google is the hiring manager—and it never hires based on the CV alone.
The “Broken SERP” Exhibit: When Google Fills Page 9 with Trash instead of Your Answer
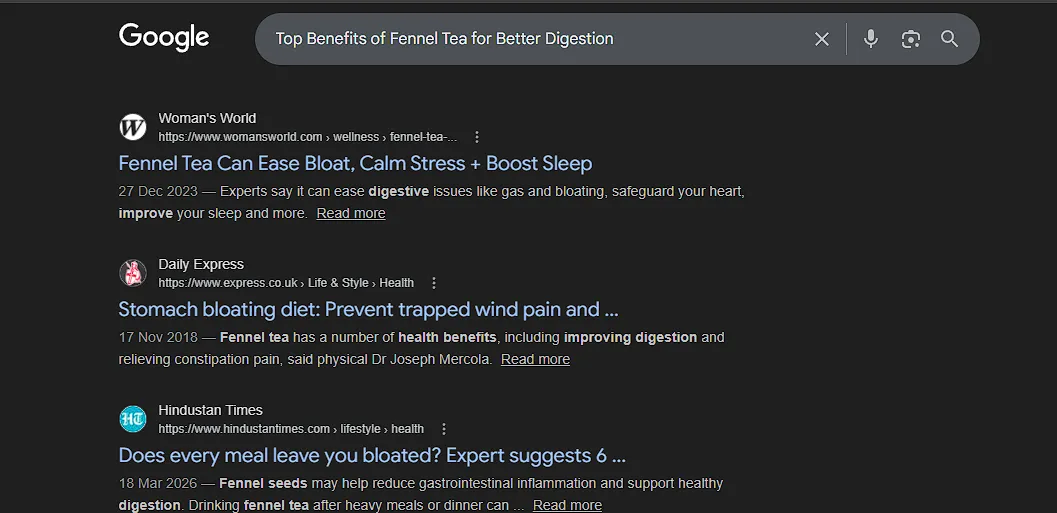
I’ve seen this happen personally while working as a content writer for several websites. You do the ultimate test: you search for your exact, full title just to see where you stand.
The Test: I searched for my specific post, “Top Benefits of Fennel Tea for Better Digestion”.
The Reality Check:
- Pages 1–6: Mostly relevant results. You see other blogs and health sites talking about tea and digestion. (The “Trusted & Relevant” zone).
- Page 7: The quality starts to dip.
- Pages 8, 9, and 10: This section is where the system looks completely broken. Instead of my perfect-match article, I see Max Hospital pages about chest pain due to gas, random Facebook posts, generic YouTube videos, and old diet charts.
- The “Fennel Tea” winner: On Page 10, a massive site ranks just because it mentions “fennel tea is good for digestion” in one tiny sentence.
- My Post: Still nowhere. My post does not even rank in the Top 100.
Why is a “Chest Pain” article or a random FB post on page 9 while my “Fennel Tea” blog is invisible?
Because Google is backfilling with safety.
Once the system finishes showing the “Trusted + Relevant” stuff on the first few pages, it runs out of sources it fully trusts. It has two choices:
- Risk showing my new, unverified blog, “The Unknown”.
- Show a Facebook post or a hospital page about gas pain (the “Verified Stranger”).
Google chooses the Verified Stranger every time. To the algorithm, that hospital page is a “Safe Bet” because the domain is a giant, even if the content doesn’t match my search. My blog is a “risky bet,” even though it’s the exact answer. Google would rather show “Trusted Trash” in the back rows than take a chance on an unproven author.
How To Get Data Even If You’re Not Ranking

This is the tricky part—the chicken and egg problem.
No rankings → no traffic
No traffic → no data
No data → no rankings
But there are ways around it.
1. Target very specific long-tail queries
Go after queries that bigger sites ignore. These are easier to rank for and can bring your first clicks.
2. Bring your own traffic
Don’t rely solely on Google at the start.
Share your content where real people are :
- Quora
Even small traffic helps build engagement signals.
3. Use internal linking properly
If one page is indexed and seen, use it to push other pages. Google follows internal links and prioritises connected content.
4. Watch Search Console closely
If you see impressions at very low positions (like 80–100), that’s a good sign. It means Google is testing your page.
From there, consistency helps it move up.
5. Publishing consistency creates a pattern of reliability
Google’s systems are watching whether you publish regularly.
Frequency in publishing content is not a direct ranking factor . But because consistent publishing over time creates what you could call a ‘base’ of reliability. Google can see that this site publishes every week. It has been doing so for two years. That pattern is a trust signal.
What You Should Actually Do (Instead of Over-fixing Content)
At this stage, repeatedly rewriting your content won’t significantly impact its effectiveness.
What you need is to build a pattern of authority over time.
Focus on a few things:
- Stay within one niche. Don’t jump topics randomly—it confuses Google’s understanding of your site.
- Publish consistently. Not daily, not aggressively—just reliably enough to show you’re active.
- Build a real identity. Include an author page, background information, and a clear reason for writing about the topic.
These aren’t quick wins. They’re signals that compound slowly—but they matter more than tweaking headings or adding FAQs.
What’s Really Happening on Pages 8–10
This part clears up a lot of confusion.
Pages 1–3 are where Google is actively trying to match intent with trusted results.
By page 4–5, authority starts dominating over relevance.
By page 8–10, Google has mostly stopped caring about precise relevance. It’s just filling space with anything that has some connection and comes from a trusted domain.
That’s why results look random.
It’s not that those pages “beat” you. It’s that Google ran out of trusted, relevant options and started backfilling.
You’re not there because you’re not part of that trusted pool yet.
Why You’re Not Ranking (in one clear line)
You’re not ranking because:
Google hasn’t verified your site as a reliable source yet.
Not because your content is weak. Not because your SEO is broken.
Just because you’re still unproven.
Read More: Read in detail why your content is not ranking and how to fix it
Final Thoughts
Currently, you’re not competing on content quality—you’re competing on trust and time.
That’s why it feels unfair. Because it kind of is, at the beginning.
But the system is consistent.
If you keep publishing in one direction, stay active, and don’t disappear, you will move slowly.
Untrusted → Observed → Tested → Trusted
And once that shift happens, your pages don’t just crawl up slowly.
They start entering the real rankings.
Not because you suddenly got better, but because Google finally believes you.
— Google does not rank the best content. It ranks the most verified content. —







