

How I Fixed “Discovered – Currently Not Indexed” When Everything Failed
You spend hours researching, writing, structuring… you hit publish, sit back for a second, maybe even feel proud of the piece. Then you open Google Search Console expecting that sweet green confirmation.
And instead, you see it.
Discovered – currently not indexed.
Day 1… fine. Day 2… okay maybe. Day 3… Now it starts getting under your skin.
So this one line can solve your problem of not indexing. Fix basics, boost internal links, use the Indexing API, and if it’s still stuck, change the URL and redirect it.
My 21st blog got indexed like it was VIP content, while the 20th one just shows ‘discovered – currently not indexed’ like it didn’t exist. Same site, same process, same internal linking. Everything is identical.
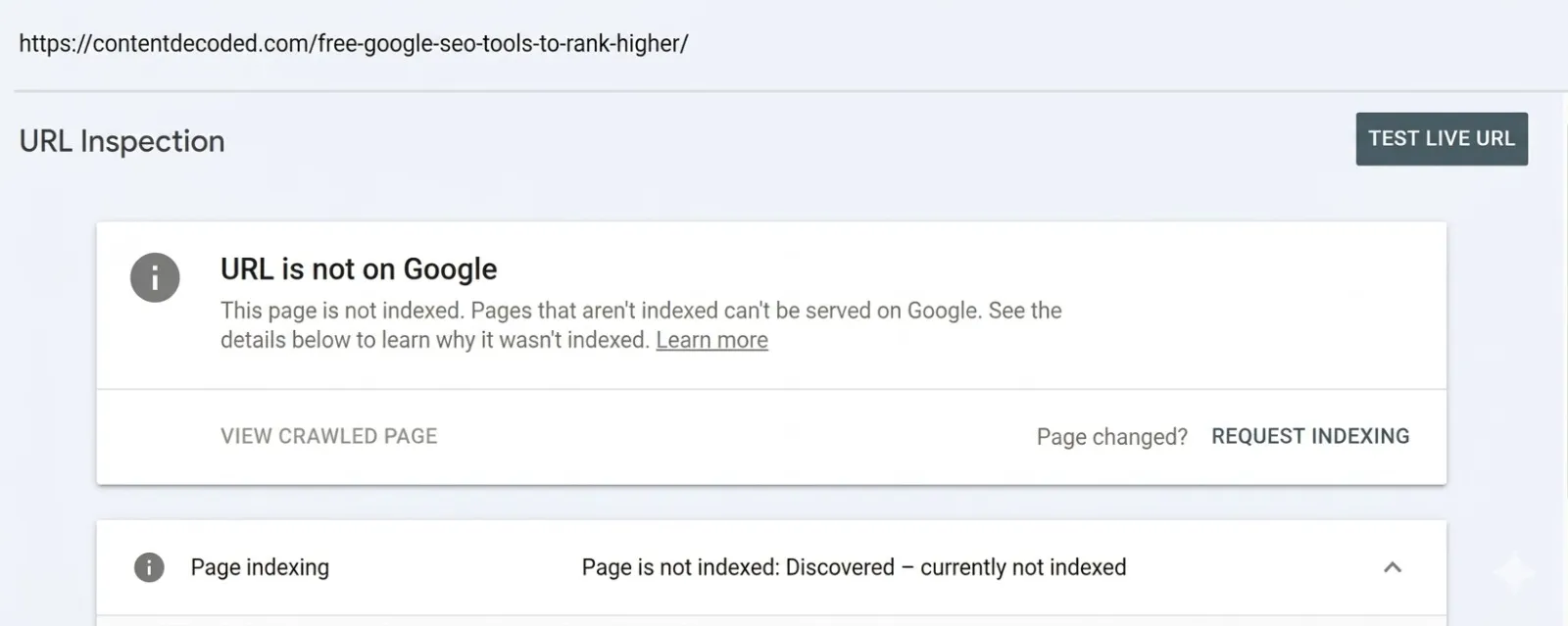
That’s when it hits me: this isn’t about “basic SEO mistakes”. This is something deeper.
And that’s exactly what this blog is about. Not generic advice. Not surface-level fixes. This is the full journey—from basics to technical to the final move that actually worked.
The Quick Answer
If you don’t want to read everything, here’s what actually moves the needle:
Check for obvious blockers like noindex tags or robots.txt restrictions. Make sure your page is actually crawlable.
Strengthen internal linking from your already indexed, high-authority pages.
Use the Google Indexing API to send a stronger signal than the normal request button.
And if your URL is still stuck for days… Change the slug, set a 301 redirect, and resubmit it.
That last one? That’s the move that got my page indexed in about two hours after being stuck for days. To know in detail, stay till last.
Let’s Start With the Basics
Even when you know you’ve done everything right, it still helps to double-check—not because you’re wrong, but because it gives you certainty before moving to advanced fixes.
First, check if your page is accidentally blocked. It sounds basic, but plugins sometimes add a noindex tag without you realising it. One wrong setting and Google won’t even consider indexing it.
Then look at your robots.txt file. If Googlebot is being blocked—even partially—it can stop crawling entirely, and in some cases it can even interfere with how Google reads noindex instructions.
Your sitemap should also be clean and successfully submitted. If your URL is listed there and still stuck, that tells you something important: Google knows about it but isn’t prioritising it.
And then comes the uncomfortable question—content quality.
Not “Is it good?” but “Is it necessary?”
Google doesn’t index pages just because they exist. If your topic is heavily covered and your version doesn’t add anything new, it quietly pushes it down the priority list.
Also, it is worse if your content is duplicated.
Harsh, but real.
When Basics Don’t Work, You Push Strategically
Once you’re confident nothing is technically broken, the game changes. Now it’s about sending stronger signals.
Internal linking is not just about adding links—it’s about where those links come from. A link from a random post won’t do much, but a link from a page that already ranks? That changes things.
Google crawls high-performing pages more frequently. If your stuck URL is linked there, it gets pulled into that crawl cycle.
Then there’s external activity.
Sharing your post on platforms like LinkedIn or Twitter isn’t about traffic alone. It creates movement. It tells Google, “This page is alive.”
Sometimes, that small push is enough to break the delay.
But not always. If it does not work also, then let’s move to the next step.
The Technical Shift: When “Request Indexing” Stops Working
Let’s be honest for a second.
That “Request Indexing” button? It often feels like a placebo. You click it. It says “Request submitted”, and then… nothing changes.
That’s because it’s just a request. It doesn’t carry priority.
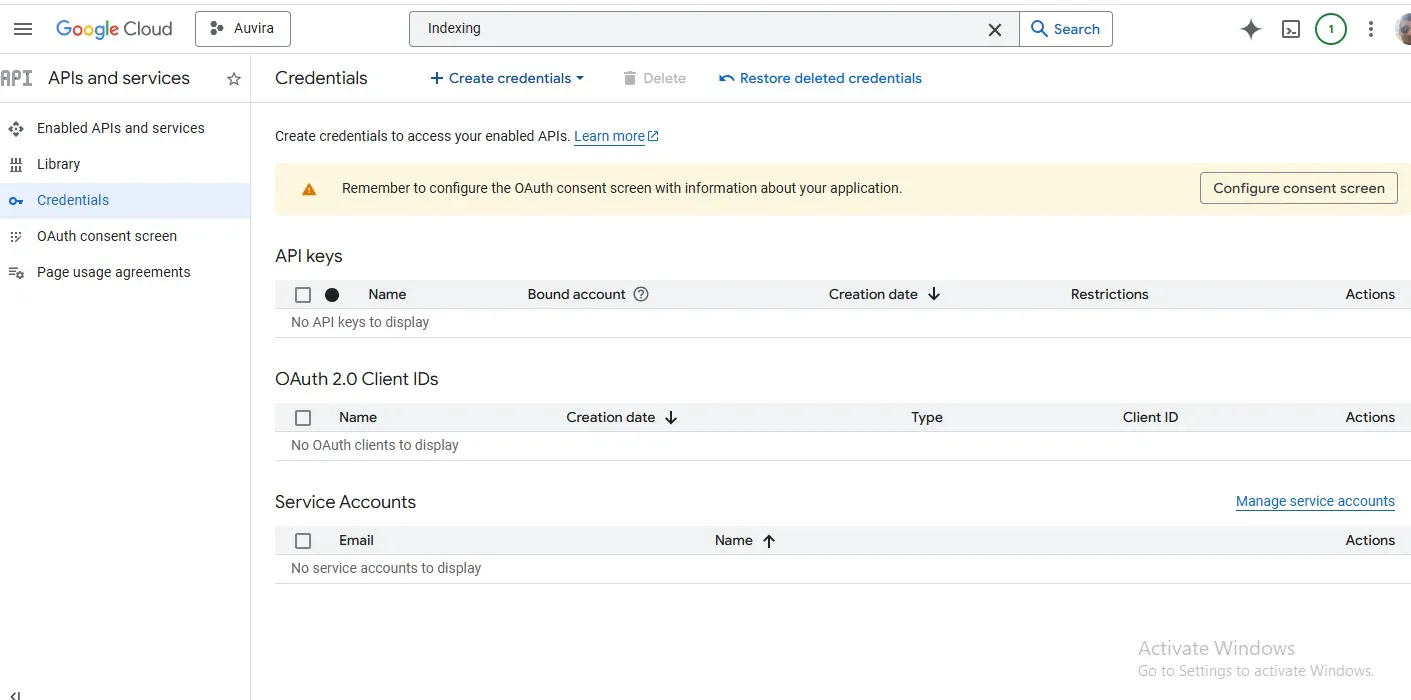
This is where setup the Google Indexing API comes in.
This isn’t widely used by casual bloggers, and that’s exactly why it works so well. Instead of politely asking Google to crawl your page, you’re directly notifying its system.
Setting it up takes a bit of effort. You go through Google Cloud Console, create a project, generate JSON keys, connect it through something like Rank Math, and authorise it in Search Console.
Once done, you can send your URL directly through the API.
In my case, I did exactly that. The API responded with success. And still… nothing happened.
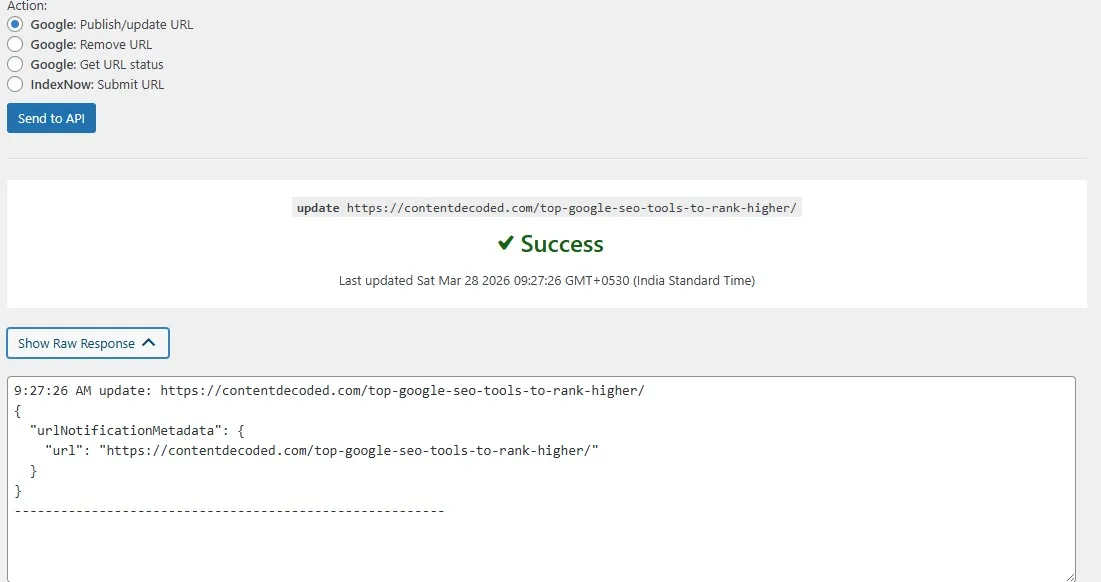
That’s the moment you realise something important. Sometimes the problem isn’t your setup.
It’s the URL itself.
The Final Move: The URL Swap Hack That Actually Worked
At this point, I stopped assuming Google would “eventually fix it.”
Instead, I changed the game.
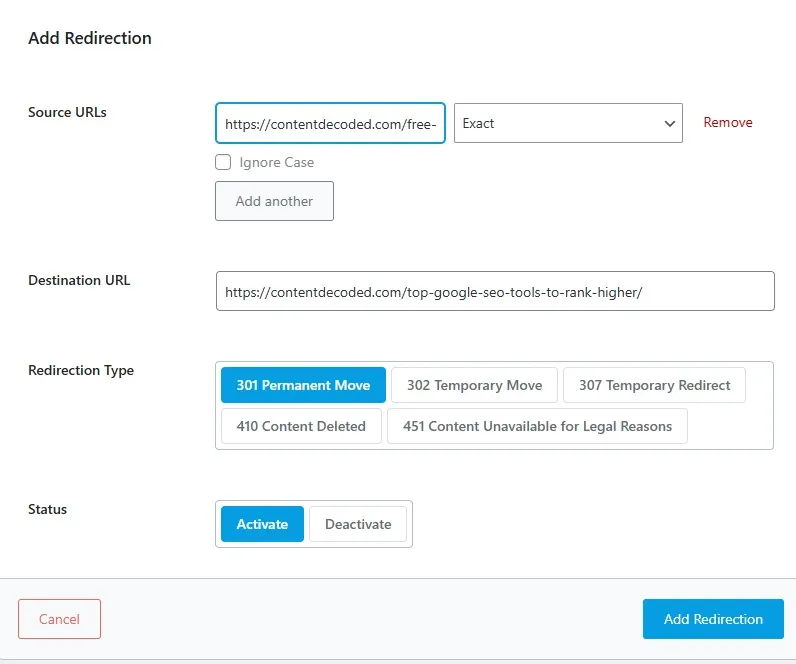
I edited the URL slug. Not a complete rewrite, just enough to make it technically a new URL.
The old one? I set a proper 301 redirect to the new one , so no link value was lost.
Then I took that new URL and sent it through the request indexing button.
What happened next almost surprised me.
A page that sat in “Discovered” for days got indexed in roughly two hours.
Here’s what this really means. Sometimes, Google’s system gets stuck on a specific URL entry. It’s not your content, not your site—just that particular record in their crawl queue.
By changing the URL, you’re essentially bypassing that stuck entry and creating a fresh one.
It’s not a trick. It’s just understanding how the system behaves.
The Backlink Myth (Or Is It Just an Optional Push?)
A lot of people will tell you to make backlinks if your content is not indexed. Honestly, that hasn’t been my experience.
If your content is solid and your technical setup is clean, Google doesn’t need external validation to crawl and index your page. It’s fully capable of doing that on its own.
That said, there’s a small nuance here. When you’ve already tried everything and the page is still stuck, a backlink can act like a signal booster. Not a requirement, not a dependency—just a nudge. If Google spots your link on an already trusted site, it might decide to crawl your page a bit sooner.
So the real takeaway is simple. Don’t treat backlinks as a hack for indexing. They’re optional. Useful sometimes, but never the core solution.
What I Learned From This Whole Mess
At the start, I thought something was wrong with my content.
Then I thought maybe I messed up technically. But later, I found that everything is okay, like my other indexed posts
What this really showed me is that Google isn’t some perfect system making flawless decisions. It’s a massive machine with queues, priorities, and sometimes… glitches.
And when that happens, waiting isn’t always the answer.
Sometimes, you need to change direction.
Final Thought
If your page is stuck in “Discovered – currently not indexed”, don’t assume you’ve failed.
But also don’t sit there refreshing Search Console for days.
Start with basics, move to strategy, use technical tools when needed, and if everything still fails… Don’t hesitate to reset the game with a URL change.
Because sometimes, the fastest way forward isn’t pushing harder.
It’s taking a slightly different path.
— trust grows in systems, not silos —








